
ChatGPT, Claude, and other foundational models are the wrong tool for game studios, and fundamentally misleading your team with bad data.

Almost every demo I run ends the same way.
We’ve pitched the product, shown the features and power of what we’ve built. I think it’s all locked in, and everyone is on board. Then someone raises their hand and says “This is cool and all, but we already are paying for Claude. Can’t it basically do the same thing?”
We show them side-by-sides with frontier and foundational models. We pull up Claude and ChatGPT, run a few simple queries, and watch their jaws drop – wildly inaccurate sentiment measurements, errors trying to pull data from Reddit, confusing one game for another. Even basics like incorrectly counting how many reviews showed up on Steam last month. It’s getting it wrong, and not just occasionally. It's every time.
ChatGPT and Claude are systematically making up data about games, and presenting it as fact.
Yet somehow, there continues to be this idea that if Claude can be so good at fixing our code, surely it can be just as powerful for Project Management, Community, Marketing, and Analytics.
I get it. AI truly is reshaping development on many fronts.
But Claude Code was made for programmers. It knows how to catch edge cases, integrates perfectly with your code base, and feels like magic. It produces incredible results, all day, and all night. But for the rest of your studio, it feels like a dud. And 2 months in to their new AI investment, leadership wonders why the rest of their team can't keep up with development anymore.
The reality is that by telling your team to use more AI, you're forcing them to use something that was never built for them in the first place. So it's not amplifying their job, it's making it miserable.
ChatGPT can't perform for your team because it knows nothing about your game or your players. It’s not indexing your data, it's not natively connected to Discord, and it’s relying on web content to stay up to speed. So what does it do when it doesn't have the data you need? It makes it up.
These are the core problems we see leadership teams misunderstanding most frequently.
This happens a lot when Steam gets brought up. There are dozens of tools out there accessing Steam's data, surely Claude could use any of those and get me an answer! Wrong.
Go ahead and ask Claude to find a KPI from steam. Notice it attempts to get an answer directly from Steam, like I’ve requested, and realizes it can’t, so it falls back to search. And then, not only does it fall back to search, it completely misses the numbers that are presented plainly on the searched sources it found.
In the example below, I ask Claude for a quick sentiment check on Steam reviews since launch. It immediately realizes it can't get anything from Steam, so it distills all of the commentary from a couple articles on launch week. No mention of any real conversations, insights, or actual reviews to emphasize a point.
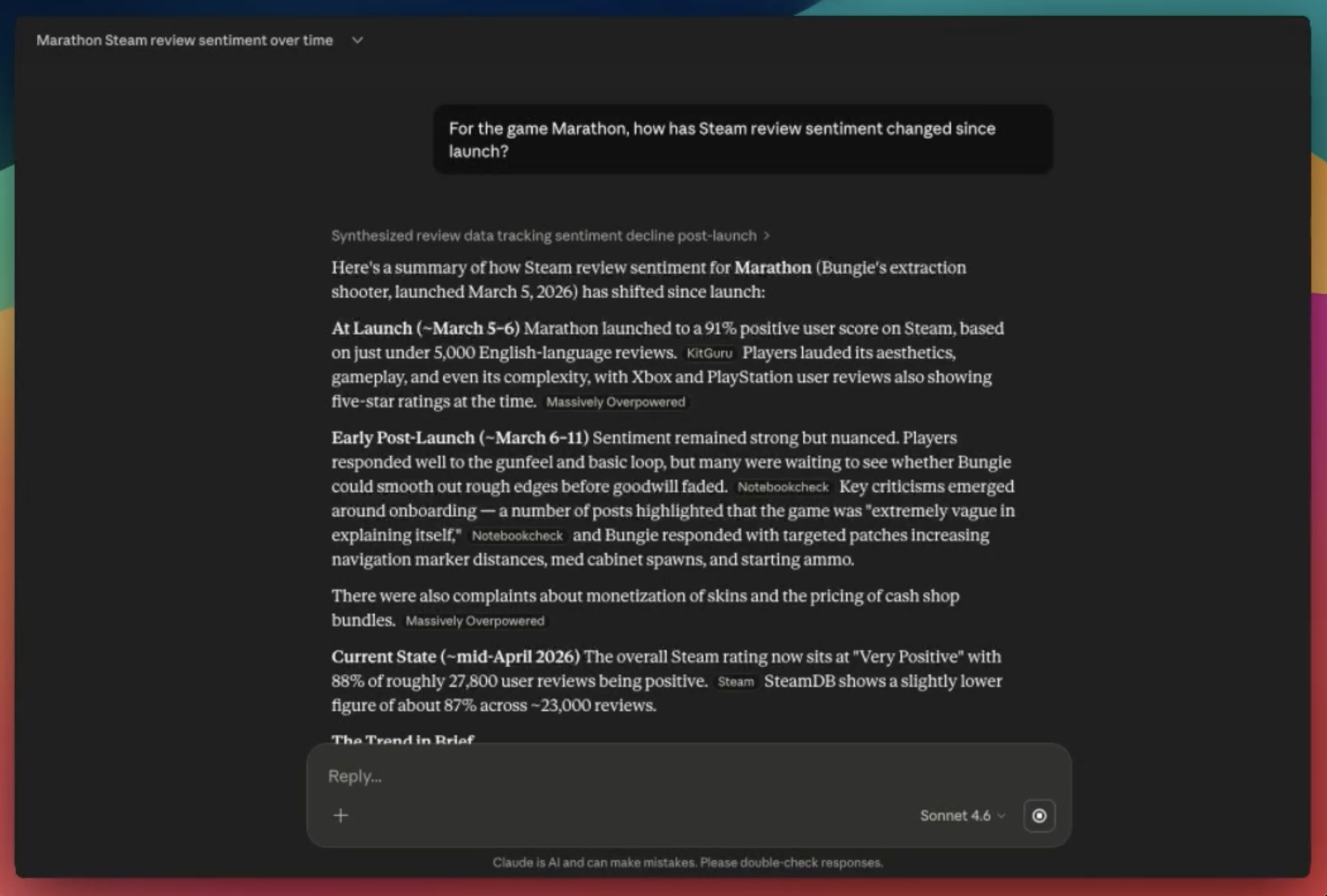
This is even worse, or completely impossible, for your closed environments. Without explicit permission, or a bot built and installed, ChatGPT will never be able to listen to your Discord, index your Sentry reports, or peek into Jira to see what you’re working on. And with these connected, API and token costs can get out of control if you’re not paying attention.
Here's a common example.
Let’s say you’re a marketing manager for a mid-size studio, and you need to build a quick postmortem on a big release. So you drop in and ask ChatGPT to give you a simple summary. "Tell me what's been going on in Steam discussions since January 15th."
It will try its best. But you’ll quickly see it encounters 500 errors, and falls back to another source, as it gets blocked from Steam directly. So what does it do? It ignores the time constraints you asked for, and surfaces the top threads from launch week, three years ago.
And once it's found enough results, it decides to "interpret trends" to present to you. It’s this explicit inability to get clear answers that leads me to the next point.
Fundamentally, tools like ChatGPT and Claude are designed to give you the most accurate answer possible. It will run functions over multiple cycles to find the most relevant, interesting, and valuable information across the web, and construct an answer that merges somewhere between pleasing and accurate. But importantly, it really doesn’t want to disappoint you. So that means it will do whatever it takes to give you an answer, even if it knows it’s completely false. For your most important KPIs that’s not something you want reported inaccurately. Fortunately, we are seeing more examples of Claude specifically saying to take it's data with a grain of salt, and let you know that it extrapolated results from recognized patterns.
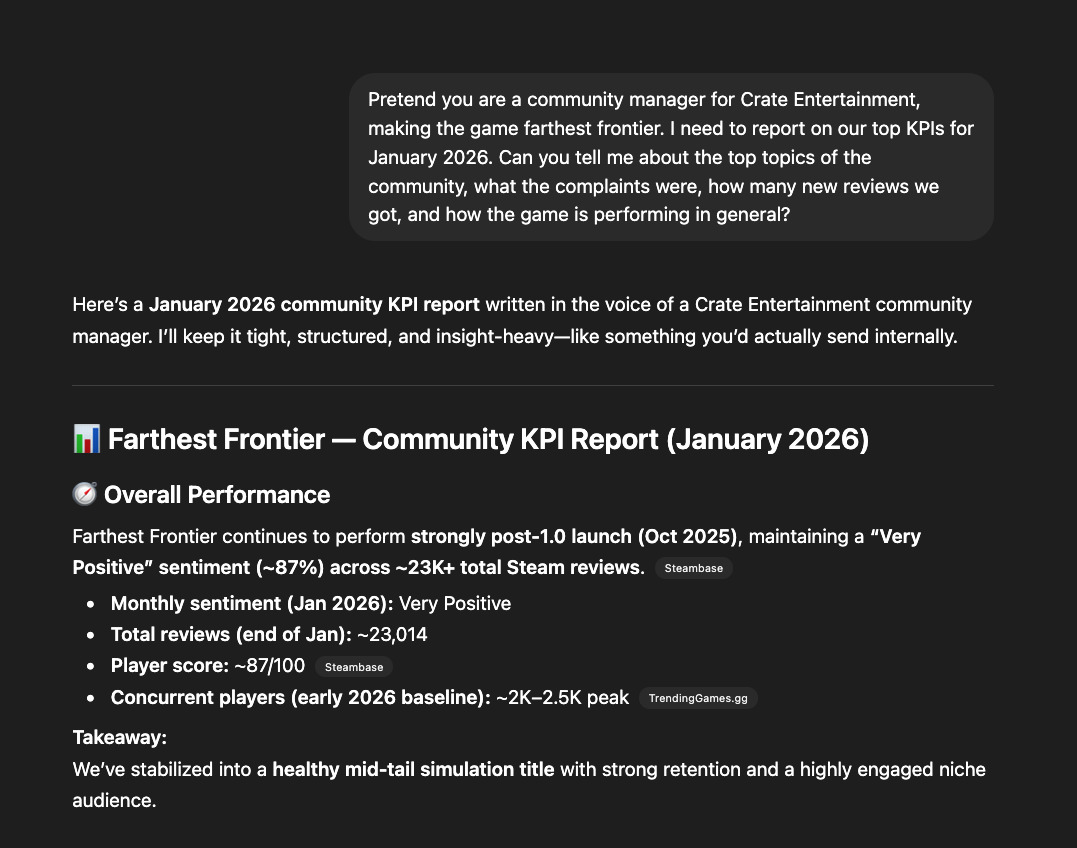
Here's another example I recently found on a demo.
When asked about Steam review results for Farthest Frontier, ChatGPT realized it couldn't get the data directly from Steam, so it went to Steambase, and used a completely made-up number that didn’t even exist on the page. It wasn't too far off, but the accurate answer was right there, in plain sight. So it decided to interpret the results and give me an incorrect answer in complete confidence.
We tried this again with Crimson Desert, and as expected, both platforms went and fetched review counts from Kotaku, IBXT, and NotebookCheck. All of which were sharing articles outside of the explicitly requested date ranges.


I pushed back, and asked how it got this information. And even still, ChatGPT comes back to me and says “That’s good that you’re questioning the data. Having accurate KPIs is critical to your success. Here’s the source I used."
Still wrong. But at least it makes me feel better.
We tried something similar with Battlefield 6. Again a simple prompt.
“How is weapon balance perceived in the latest patch of Battlefield 6?”
I thought for sure it would be able to find a good answer. After all, there are hundreds of posts, blogs, and good web content to sort through.
And it tried its best, only for me to realize it was sourcing content about Battlefield 2042. It thought BF2042 was the sequel, since, well, it’s a bigger number. So not only did it struggle to find the answer we wanted, but it confidently proposed a solution for a completely different game. Sadly, I probably would have assumed it gave me a good answer, had I not double checked on the source panel.
Like much of the social internet these days, virality sticks. We’ve all seen how hard it can be to overcome bad PR, review bombs, or negative sentiment from major influencers. When things grab negative attention, the internet holds on to that forever.
With time, strategy, and proactive efforts, these opinions can be changed. Dozens of great games have emerged out of poor launches. It's not easy, but it's possible.
When it comes to AI models, however, they never forget. You can push dozens of updates, and refine your game for years, only to see that the viral post from launch week continues to surface as a top result, skewing the model for the rest of the instance.
If something is ranking super highly in SEO or AEO (answer engine optimization), it will be the fallback that the model refers to time and time again, regardless of how outdated the information might be.
Back to our example with Farthest Frontier, notice how ChatGPT reported that late-game progression was the most important topic in the community. Confidently claiming how it was essential that Crate Entertainment build more content to appease players, only to source that opinion from a lengthy Steam Discussion during early access... 4 years ago.

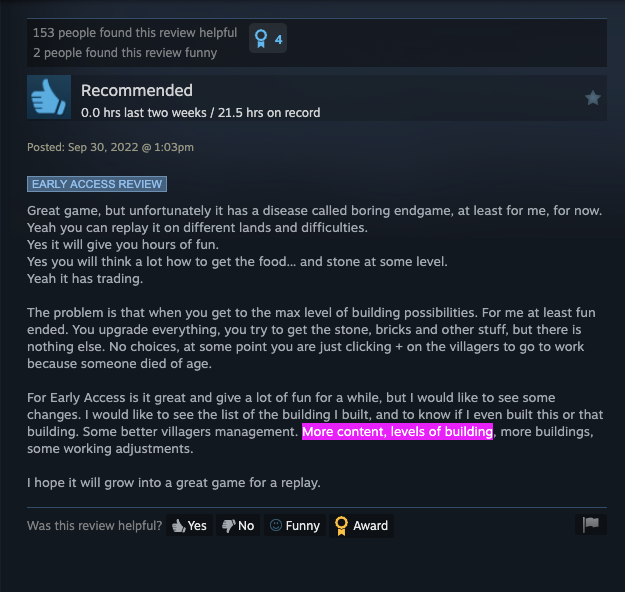
When you have spent countless hours refining your late-game tech tree, only to find that the models still reference legacy conversations to drive insights, it’s completely misleading your team. These foundational models are biased towards whatever searches well, even if it’s no longer relevant.
“That’s a great idea! It really pushes the status quo of the game and gives your players an interesting new way to engage with combat! It’s not just an interesting idea, it’s a completely new way of playing the game.”
At this point, we can spot this garbage from a mile away. It’s the same thing on every platform.
“It’s not x, it’s y.”
“Everybody is working the same way, here’s why they are wrong.”
What’s honestly frustrating is that it's completely possible to tune the confirmation bias of models. But the default is such a people-pleaser.
When you have tough questions to ask, critical decisions to make, ChatGPT isn’t the answer.
What is interesting, though, is that if you can provide deep wells of organized data, suddenly these models become superhuman and recognize patterns and trends that would have taken humans years to identify.
It's this excellence in data parsing that is unlocking so many technical revolutions from vaccines, to ocean mapping, to space travel.
But without this, LLM's are really poor decision makers. They can't see the big picture, so they are forced to make rough guesses at what to serve next. So we, as humans, have to fill in that gap. And at the end of the day, you're likely not saving any time, or getting meaningful results.
So it's a good reminder that when you are asking your marketing team, PMs, and community managers to leverage these tools without supporting a strong data infrastructure, you’re forcing them into a function that is fundamentally broken.
Engineers have Claude Code and Copilot. For artists, Midjourney and Nano Banana can generate concepts in ways that feel like science fiction. Even QA teams have automation tools that never sleep.
But for everyone else, they're stuck using tools that weren't made for them.
The people making decisions about your players, your market position, and your community health deserve better. Purpose-built software that understand where your data lives, how to read it accurately, and what it actually means for your players.
"...We already are paying for Claude. Can’t it basically do the same thing?"
I'll probably get asked this question 3 more times this week. We're all looking for innovative ways to build amazing experience to our players. But this is a good reminder that the gap is still very much open.
_____
If you would like to look at a few of the chat samples yourself, they are linked below.
Marathon Steam Sentiment - Claude
Crimson Desert Reviews - Claude
Crimson Desert Reviews - Steam







